Problem Statement
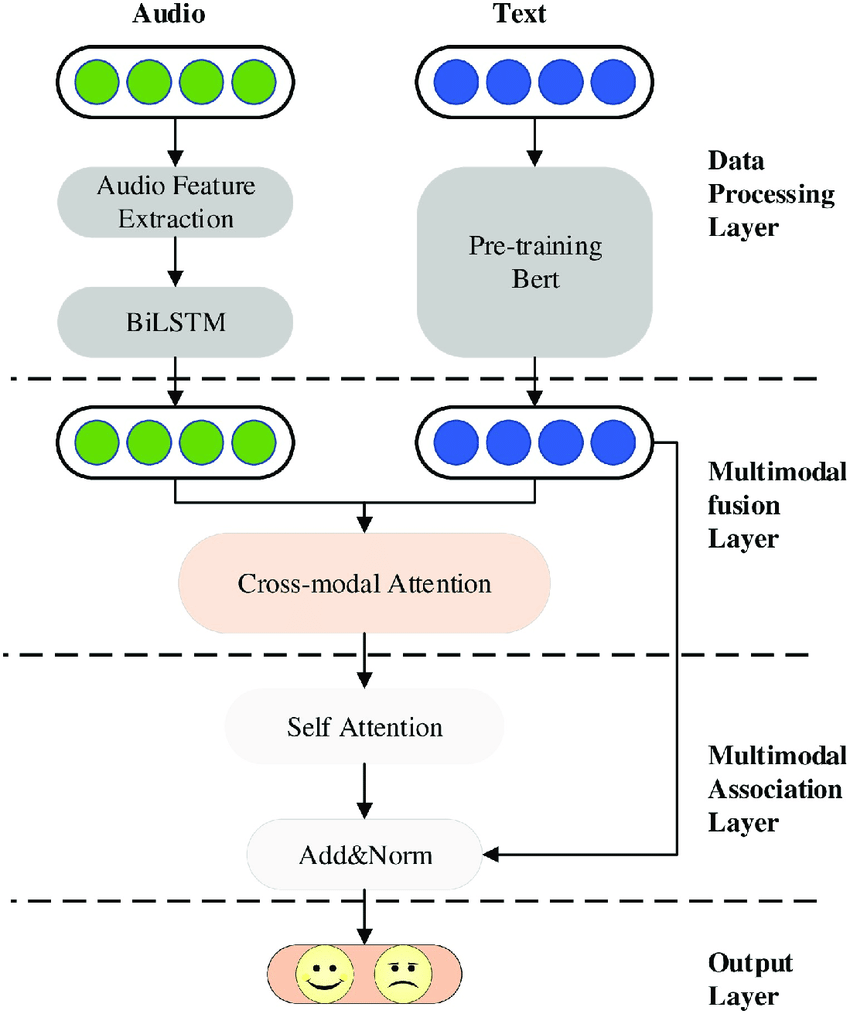
The Action Item Detection project focuses on extracting action items from email and conversational transcripts. The goal is to develop a model that can accurately identify action items within the text data. Additionally, sentiment analysis is performed on the detected action items to identify roadblocks and further action steps. The project utilizes BERT (Bidirectional Encoder Representations from Transformers) model for action item detection.
Solution Overview
- Data Preprocessing and Annotation: The initial step involved preprocessing and cleaning the email and conversational transcripts data. This process included removing irrelevant information, such as signatures and formatting tags, and standardizing the text data. The cleaned data was then annotated, assigning a label of 1 to text segments that contain action items and a label of 0 to non-action items. Annotation ensured the availability of labeled data for training the BERT model.
- BERT Model Training: The BERT model with 12 layers was initially trained using the annotated data. This model had a size of 550 MB and achieved an accuracy of 87%. However, the large size posed challenges for deployment and inference. To address this, a DistilBERT model with 6 layers was employed, reducing the size to 320 MB while maintaining the same accuracy of 87%. Further size reduction was achieved by reducing the number of layers to 1, resulting in a model size of 128 MB. However, this reduction in layers led to a decrease in accuracy, down to 78%.
- Improving Model Performance: To regain the accuracy lost during size reduction, efforts were made to improve the quality and quantity of the training data. Additional annotated data was collected and integrated into the training set. Careful attention was given to the quality of the data to ensure accurate annotations. This improved data set allowed the model to achieve a higher accuracy of 90% while still maintaining the reduced size of 128 MB.
Tech Stack leveraged
To make the model framework independent and optimize inference time, the final trained model was exported to the ONNX (Open Neural Network Exchange) format. ONNX ensures compatibility with various deep learning frameworks and enables efficient deployment. The model was deployed using AWS Lambda, AWS EFS (Elastic File System), and AWS EC2 (Elastic Compute Cloud) services. This deployment setup allowed for scalable and efficient inference of action items within the provided text data.
Benefits Delivered
The Action Item Detection project successfully developed a BERT-based model for accurately identifying action items in email and conversational transcripts. By reducing the model size from 550 MB to 128 MB, the deployment and inference efficiency were significantly improved. The model achieved an accuracy of 90% after improving the quality and quantity of the training data. The ONNX export made the model framework independent, enabling easy integration with different deep learning frameworks. Overall, the project delivered an effective solution for automating action item detection and sentiment analysis, facilitating efficient decision-making and task management based on textual data.
The developed model can serve as a foundation for further enhancements and applications. Future work may include incorporating multi-modal data sources, such as audio or video, for more comprehensive action item detection. Exploring transfer learning techniques and domain adaptation can also improve the model’s performance in specific contexts or industries. Additionally, continuous monitoring and updating of the model can ensure it remains effective as language patterns and communication styles evolve over time.